AWS S3 にデータをアンロードする
このトピックでは、CelerData から AWS S3 バケットにデータをアンロードする方法について説明します。
ステップ 1: S3 バケットのアクセス ポリシーを設定する
AWS アクセス制御要件
CelerData がフォルダーおよびそのサブフォルダー内のファイルにアクセスできるようにするには、S3 バケットおよびフォルダーに次の権限が必要です。
s3:GetObjects3:PutObjects3:DeleteObjects3:ListBucket
IAM ポリシーの作成
次のステップバイステップの手順では、AWS マネジメント コンソールで CelerData のアクセス許可を設定し、S3 バケットを使用してデータをアンロードできるようにする方法を説明します。
-
AWS マネジメント コンソール にログインします。
-
ホーム ダッシュボードから Identity & Access Management (IAM) を選択します。
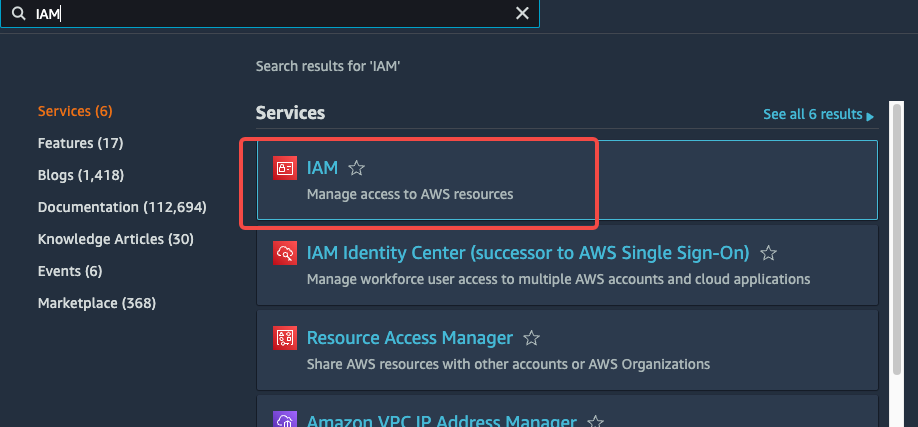
-
左側のナビゲーション ペインから Account settings を選択します。
-
Security Token Service Regions リストを展開し、CelerData クラスターがデプロイされている AWS リージョンを見つけ、ステータスが Inactive の場合は Activate を選択します。
-
左側のナビゲーション ペインから Policies を選択します。
-
Create Policy をクリックします。

-
JSON タブをクリックします。
-
CelerData が S3 バケットおよびフォルダーにアクセスできるようにするポリシー ドキュメントを追加します。
次の JSON 形式のポリシーは、指定されたバケットおよびフォルダー パスに対する CelerData の必要なアクセス権限を提供します。ポリシー エディターにテキストをコピーして貼り付けることができます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket_name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
],
"Resource": [
"arn:aws:s3:::<bucket_name>/*"
]
}
]
}NOTE
<bucket_name>をアクセスしたい S3 バケットの名前に置き換えてください。たとえば、S3 バケットがbucket_s3という名前の場合、<bucket_name>をbucket_s3に置き換えます。 -
Review policy をクリックします。
-
ポリシー名(例:
celerdata_export_policy)とオプションでポリシーの説明を入力します。次に、Create policy をクリックしてポリシーを作成します。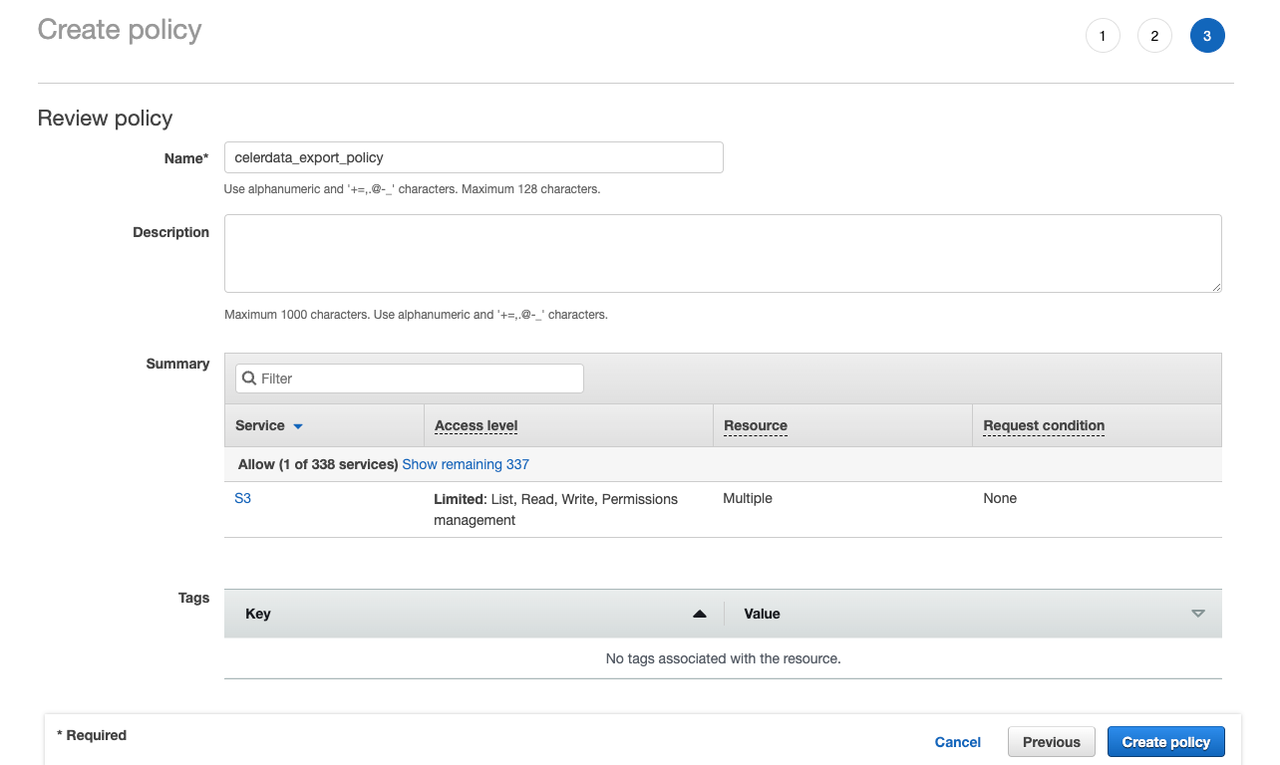
ステップ 2: IAM ユーザーを作成する
-
左側のナビゲーション ペインから Users を選択し、Add user をクリックします。
-
Add user ページで、新しいユーザー名(例:
celerdata_export)を入力し、アクセス タイプとして Access key - Programmatic access を選択し、Next: Permissions をクリックします。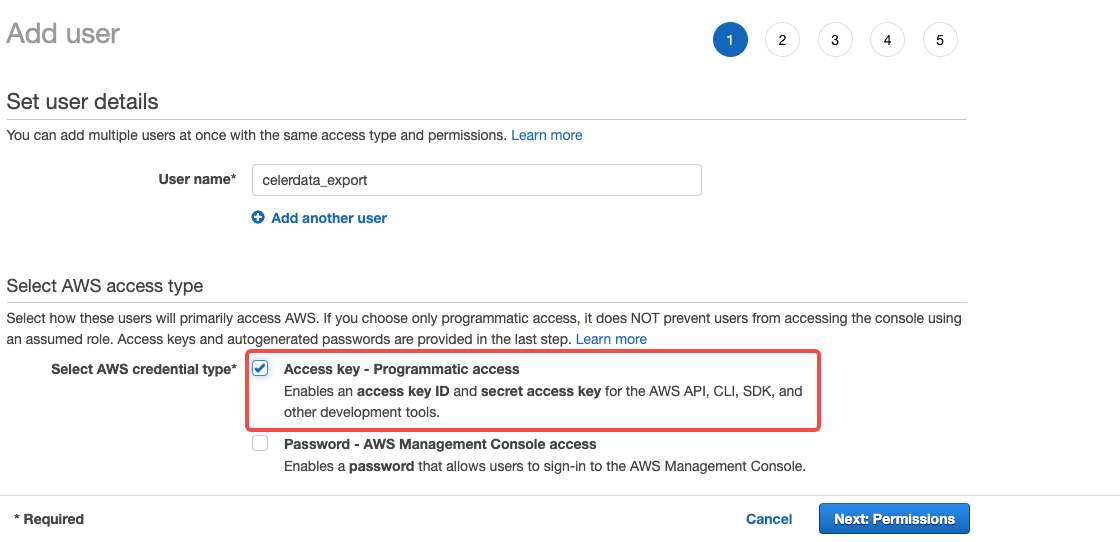
-
Attach existing policies directly をクリックし、先ほど作成したポリシーを選択し、Next: Tags をクリックします。
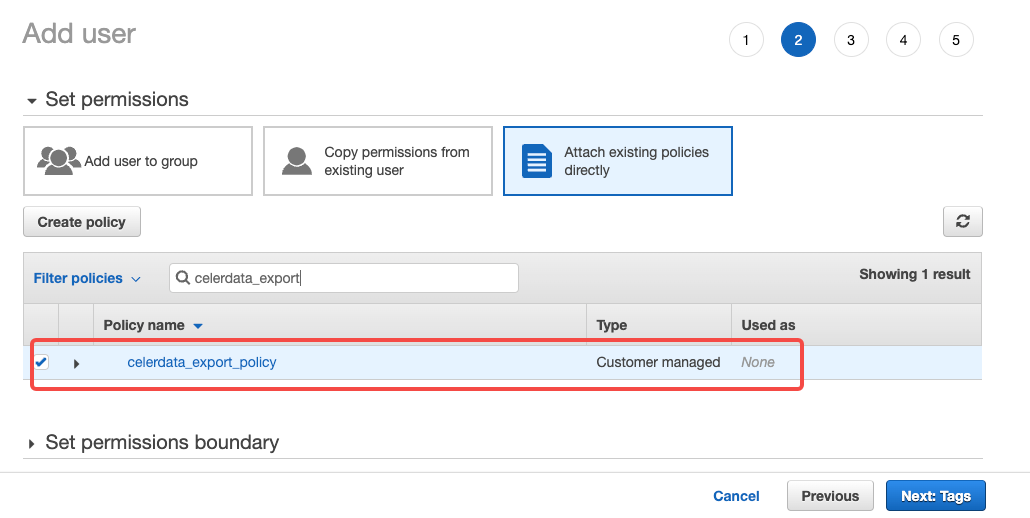
-
ユーザーの詳細を確認します。次に、Create user をクリックします。
-
アクセス資格情報を記録します。最も簡単な方法は、Download Credentials をクリックしてファイル(例:
credentials.csv)に書き込むことです。
NOTICE
このページを離れると、Secret Access Key は AWS マネジメント コンソールのどこにも表示されなくなります。キーを紛失した場合は、ユーザーの新しい資格情報セットを生成する必要があります。
これで次のことが完了しました。
- S3 バケット用の IAM ポリシーを作成しました。
- IAM ユーザーを作成し、ユーザーのアクセス資格情報を生成しました。
- ポリシーをユーザーにアタッチしました。
AWS アクセス キー (AK) とシークレット キー (SK) を使用して、CelerData で broker load を使用してバケットにアクセスするために必要な資格情報を取得しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket_name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket_name>/*"
]
}
]
}
ステップ 3: AWS S3 にデータをアンロードする
バージョン 3.2 以降、CelerData はテーブル関数 FILES() を使用してリモートストレージに書き込み可能なテーブルを定義することをサポートしています。その後、INSERT INTO FILES を使用して CelerData からリモートストレージにデータをアンロードできます。
CelerData がサポートする他のデータエクスポート方法と比較して、INSERT INTO FILES を使用したデータのアンロードは、より統一された、使いやすく、豊富な機能を備えたインターフェースを提供します。SELECT ステートメントを使用してデータをロードしたのと同じ構文を使用して、リモートストレージに直接データをアンロードできます。さらに、Parquet、ORC、および CSV (バージョン 3.3 以降) 形式のファイルへのデータのアンロードをサポートしています。したがって、ほとんどの場合、INSERT INTO FILES は EXPORT よりも推奨されます。
NOTE
Amazon S3 からのデータアンロードには S3A プロトコルが使用されます。したがって、指定するファイルパスは
s3a://プレフィックスで始める必要があります。
INSERT INTO FILES を使用したデータのアンロード (推奨)
INSERT INTO FILES を使用したデータのアンロードは、さまざまなファイル形式 (Parquet、ORC、および CSV (バージョン 3.3 以降でサポート))、圧縮アルゴリズム、および Partition By Column や単一のデータファイルの出力などの便利な機能を備えています。
INSERT INTO FILES を使用すると、テーブル全体のデータや複雑なクエリの結果をアンロードできます。
-
次の例では、テーブル
user_behaviorのデータをすべて Parquet 形式のファイルにアンロードします。INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'parquet', -- Parquet 形式のファイルとしてデータをアンロードします。
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior; -
次の例では、
2020-01-01から2024-01-01までのデータを、WHERE 句とジョインを含む複雑なクエリを使用してアンロードします。データは LZ4 圧縮アルゴリズムを使用して ORC 形式のファイルとして保存され、データは月ごとに (dt列に基づいて) パーティション分割され、user_behavior/の下の異なるディレクトリに分配されます。INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'orc', -- ORC 形式のファイルとしてデータをアンロードします。
'compression' = 'lz4', -- LZ4 圧縮アルゴリズムを使用します。
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com',
'partition_by' = 'dt' -- データを月ごとに異なるディレクトリにパーティション分割します。
)
SELECT tb.*, tu.name FROM user_behavior tb
JOIN users tu on tb.user_id = tu.id
WHERE tb.dt >= '2020-01-01' and tb.dt < '2024-01-01';NOTE
partition_byパラメーターは、指定された列に基づいてデータをパーティション分割し、データをprefix/<column_name>=<value>/形式のサブディレクトリに保存します。たとえば、mybucket/path/to/user_behavior/dt=2020-01-01/です。 -
次の例では、カラムセパレータをカンマ (
,) として、単一の CSV 形式のファイルにデータをアンロードします。INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'csv', -- CSV 形式のファイルとしてデータをアンロードします。
'csv.column_separator' = ',', -- カラムセパレータとして `,` を使用します。
'single' = 'true', -- データを単一のファイルに出力します。
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior; -
次の例では、最大サイズが
100000000バイトの複数の Parquet 形式のファイルにデータをアンロードします。INSERT INTO FILES(
'path' = 's3a://<bucket_name>/path/to/user_behavior/',
'format' = 'parquet',
'target_max_file_size' = '100000000', -- 各ファイルの最大サイズを 100000000 バイトに設定します。
'aws.s3.access_key' = '<your_access_key_id>',
'aws.s3.secret_key' = '<your_secret_access_key>',
'aws.s3.endpoint' = 's3.<region_id>.amazonaws.com'
)
SELECT * FROM user_behavior;
| Parameter | Description |
|---|---|
| bucket_name | データをアンロードしたい S3 バケットの名前です。 |
| format | データファイルの形式です。有効な値: parquet、orc、csv。 |
| compression | データファイルに使用される圧縮アルゴリズムです。このパラメーターは、Parquet および ORC ファイル形式でのみサポートされています。有効な値: uncompressed (デフォルト)、gzip、snappy、zstd、lz4。 |
| aws.s3.access_key | S3 バケットにアクセスするために使用できるアクセスキー ID です。 |
| aws.s3.secret_key | S3 バケットにアクセスするために使用できるシークレットアクセスキーです。 |
| aws.s3.endpoint | S3 バケットにアクセスするために使用できるエンドポイントです。エンドポイントの region_id は、S3 バケットが所属する AWS リージョンの ID です。 |
| partition_by | データファイルを異なるストレージパスにパーティション分割するために使用される列のリストです。複数の列はカンマ (,) で区切ります。 |
| csv.column_separator | CSV 形式のデータファイルに使用されるカラムセパレータです。 |
| single | データを単一のファイルにアンロードするかどうかです。有効な値: true および false (デフォルト)。 |
| target_max_file_size | アンロードされるバッチ内の各ファイルの最大サイズのベストエフォートです。単位: バイト。デフォルト値: 1073741824 (1 GB)。アンロードされるデータのサイズがこの値を超える場合、データは複数のファイルに分割され、各ファイルのサイズはこの値を大幅に超えません。 |
詳細な手順と関与するすべてのパラメーターについては、FILES() を参照してください。
EXPORT を使用��したデータのアンロード
EXPORT ステートメントを使用して、テーブル全体のデータまたはテーブルの特定のパーティションのデータのみを S3 バケットにアンロードできます。
EXPORT TABLE <table_name>
[PARTITION (<partition_name>[, <partition_name>, ...])]
TO "s3a://<bucket_name>/path/to"
WITH BROKER
(
"aws.s3.access_key" = "<your_access_key_id>",
"aws.s3.secret_key" = "<your_secret_access_key>",
"aws.s3.endpoint" = "s3.<region_id>.amazonaws.com"
);
次の表は、パラメーターを説明しています。
| Parameter | Description |
|---|---|
| table_name | データをアンロードしたいテーブルの名前です。 |
| partition_name | データをアンロードしたいパーティションの名前です。複数のパーティションを指定する場合は、パーティション名をカンマ (,) とスペースで区切ります。 |
| bucket_name | データをアンロードしたい S3 バケットの名前です。 |
| aws.s3.access_key | S3 バケットにアクセスするために使用できるアクセスキー ID です。 |
| aws.s3.secret_key | S3 バケットにアクセスするために使用できるシークレットアクセスキーです。 |
| aws.s3.endpoint | S3 バケットにアクセスするために使用できるエンドポイントです。エンドポイントの region_id は、S3 バケットが所属する AWS リージョンの ID です。 |
詳�細については、EXPORT を参照してください。
制限事項
- 資格情報として使用される AWS AK と SK が必要です。
- INSERT INTO FILES を使用したデータのアンロードの場合:
- CSV 形式のファイルの出力はバージョン 3.3 以降でのみサポートされています。
- CSV 形式のファイルに対する圧縮アルゴリズムの設定はサポートされていません。